Query
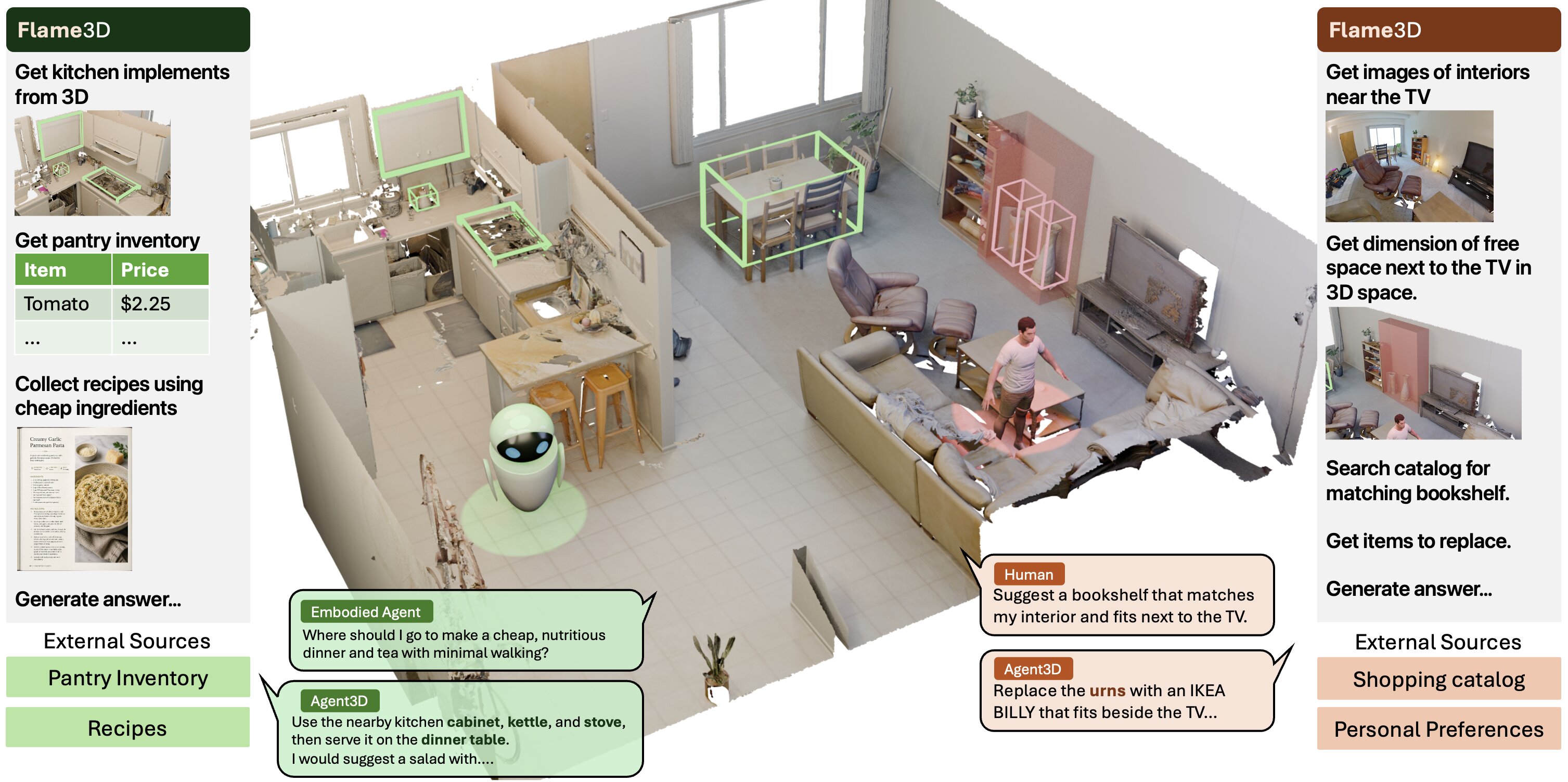
I want to move the copier elsewhere so that we have can have foosball table. Do you have a better placement of the foosball table in mind? Create a box keeping dimensions of an average foosball table and 2 players playing on it, and no other objects overlapping the box.
Speed
What gets composed
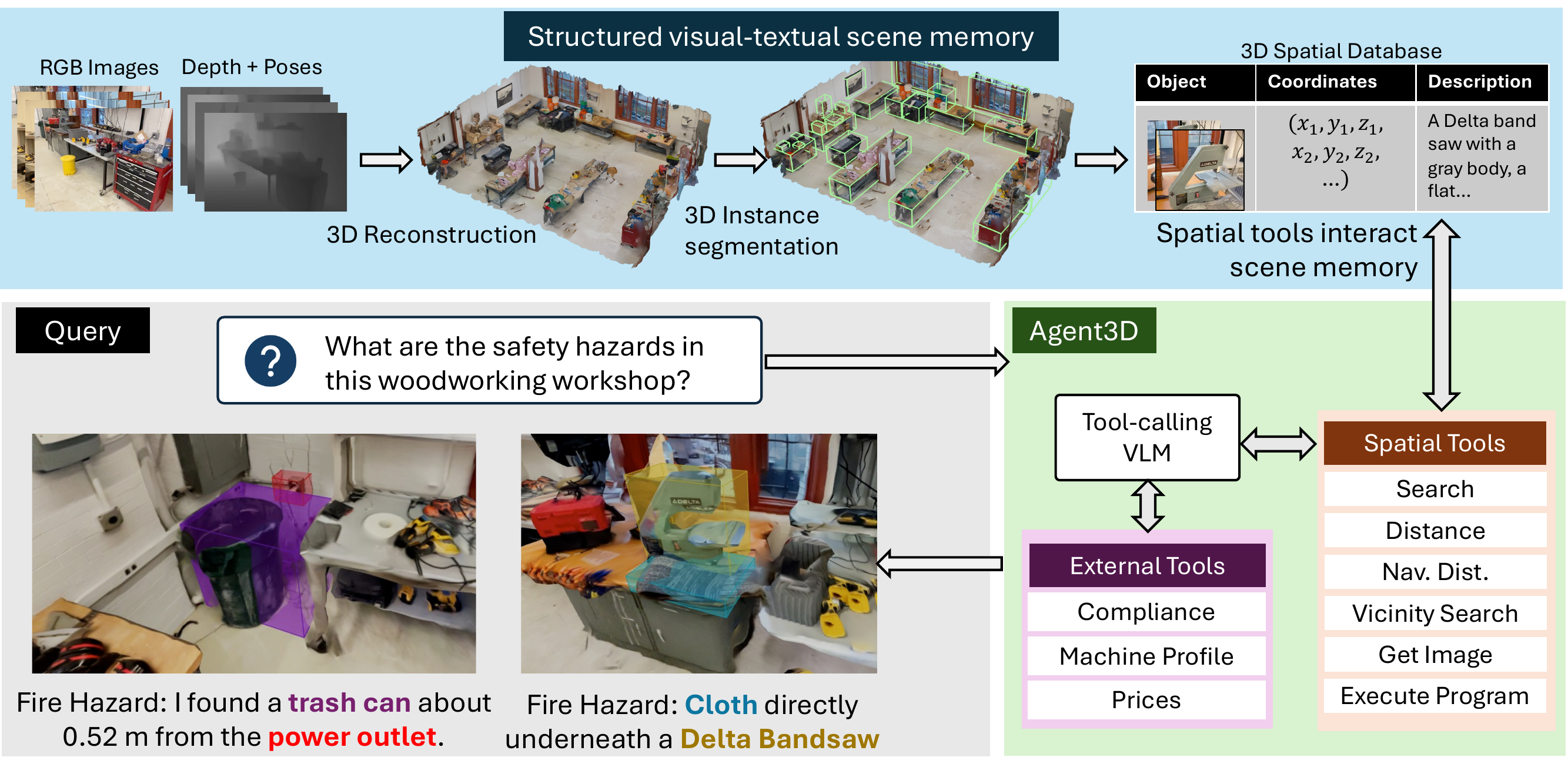
Search
Web Retrieval
Vicinity Search
Execute Code